Breaking decryption.ch: the CTF that wasn't meant to be
This article is a write up regarding the challenge published on decryption.ch by the Ex0-Sys company. Even if I resolved it in 2019, it took me a bit of time and motivation to write and finalize that blog post. Better late than never, as they say.
Anyway, this post describes how the challenge has been broken, from reverse engineering the software to actually decrypting the provided secure container.
The source code that breaks the challenge is available on Github.
 A screenshot of the decryption.ch web site
A screenshot of the decryption.ch web site
The AlphaTav software
The challenge is about assessing the cryptography strength of the AlphaTav software. This software claims various security properties:
- being quantum resistant
- time limitation
- destruction on bad credentials
- computer hardware restriction (based on a technology named Ex0-UiD)
- final encryption key up to 87000 bits
- over encryption with conventional algorithms (AES256/3DES/RC2)
Some of these properties (like time limitation & destruction on bad credentials) are “enforced” by the AlphaTav client itself. As you might imagine, this holds as long as you don’t have any other code that would implement the same algorithm.
Moreover, the AlphaTav software has multiple particularities that need to be defined in order to make the rest of the writeup easier to follow:
- a container is separated into four files:
ATK3: a file that contains settings (e.g. used algorithms, time restriction & so on) and some key materialATD/ATK1/ATK2: encrypted data split in three parts
- multiple raw key materials: password & PIN code.
- multiple levels of security:
Surprisingly enough, and as we will see in the sections below, the Exo-UID isn’t used as key material and is just a test performed by the decryption process that verifies that the expected hardware is present (see previous remark on time limit). Moreover:
- the PIN code is a 16-byte random buffer saved as a bar code. It is generated by the software when encrypting, and is needed to decrypt.
- the password is optional and provided by the user.
We’ll discuss the various claims in the following sections. Let’s now take a look at the actual challenge.
The challenge material
We are provided with:
- a 460MB container encrypted with:
- Vault level 3 (4 files, PIN code, password)
- Hardware restrictions (4 USB keys + various computers)
- Time limitation
- Destruction on bad credentials
- the AlphaTav version used to make this container, as a Windows installer
- a free 30 days licence on demand
What we don’t have:
- The password used to encrypt this container
- The generated PIN-code
If we manage to decrypt the container, we are supposed to find a video with the instructions to validate the challenge.
Methodology
So we have to crack an encrypted container, without the raw key material that was used to create it, and without a description of the proprietary algorithm that has been used. The methodology I use for these cases is somehow always the same:
- reverse engineer the application to understand the underlying algorithms and/or file formats
- reimplement an encryption and/or decryption tool it in a language that allows fast prototyping and provides a cryptography toolbox with the usual primitives (in this case Python has been used)
- create a container similar to the one of the challenge, but whose original content is known (can help figuring out implementation errors)
- emit hypothesis about potential cryptographic vulnerabilities
- play with our implementation and container to prototype attacks and (in)validate the previous hypothesis
- repeat until it works, or until we can demonstrate that it will require a bruteforce we won’t be able to perform
In this case, I started to understand the decryption routine, but doing so with the encryption one would also work. Per design, you should be able to derive one from the other.
One of the hardest part in this is the reverse engineering job to create a third party implementation we can toy with. We need to be rigorous here, as a minor mistake in the algorithm reversing/implementation can be hard to detect and cause potentially valid attacks to fail. One way to make this not too much of a pain is to extract as much test vectors as possible from the original application for every step of the algorithm (e.g. using a debugger), and use these vectors to validate our custom implementation.
So let’s go through all these steps!
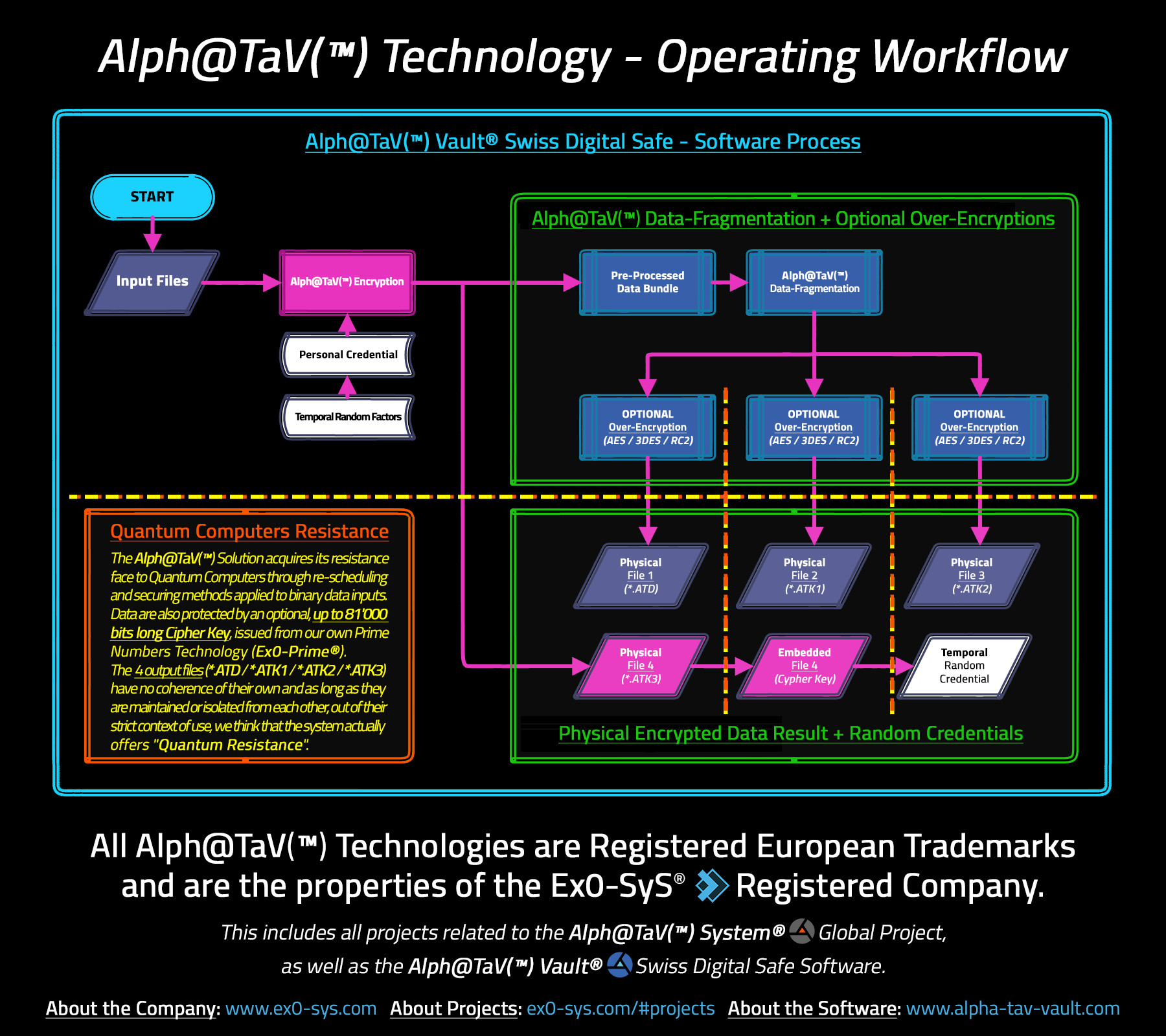
Reverse engineering
The only thing in our possession to figure out the encryption algorithm(s) is the AlphaTav software, which is an obfuscated .Net application. We can also gather public information about what is supposed to happen at least on a high level view:
Deobfuscation / debugging
In order to do a first static analysis, we used the very efficient de4dot software, which can deobfuscate a large variety of protectors.
Fortunately for us, de4dot detects that the AlphaTav software has been obfuscated with CryptoObfuscator… twice. Indeed, some libraries also have to be deobfuscated again, still using de4dot.
What’s nice about this tool is that it can generate a proper binary that just runs. So we can now use dnSpy to debug and analyze the software.
Now that we are in a more comfortable position, our main goal was to follow two data flows: the one that starts from clear data to encrypted data, and the one that starts from raw key material (the password / PIN code) to whatever derivations might happen, all towards the convergence of these two flows to the final encrypted data.
The decryption algorithm
After tedious reading of .Net code, and some debugging session to be sure everything was correctly understood, here is a scheme of the decryption algorithm as understood after reverse engineering:

This is a bit huge, so let’s discuss the various parts of this algorithm.
The fragmentation algorithm (ATD/ATK1/ATK2)
The AlphaTav fragmentation algorithm is an encoding process that splits a byte into three different values. In the AlphaTav software, each of these values are stored in different files:
- AlphaTav (
AT), stored inATK1 - Block sizes (
BS), stored inATK2. This file is not encrypted. - Bit indexes (
BI), stored inATD
Here is a Python code describing how an 8-bit value is encoded:
class EncodedData:
def __init__(self, V):
BC = BitCount(V)
self.AT = (BC == 8) or (BC > 0 and BC <= 4)
if V == 0xFF or V == 0:
self.BS = 0
else:
self.BS = BC if self.AT else (8-BC)
self.BI = 0
if V != 0xFF and V != 0:
for i in reversed(range(8)):
b = (V >> i) & 1
if (int(self.AT) == b):
self.BI = 10*self.BI + (7-i)
And a few examples:
| V | bin(V) | Bit count | AT | BS | BI |
|---|---|---|---|---|---|
| 0x07 | 0b00000111 | 3 | 1 | 3 | 567 |
| 0xAF | 0b10101111 | 6 | 0 | 2 | 13 |
| 0x2F | 0b00101111 | 5 | 0 | 3 | 13 |
| 0x00 | 0b00000000 | 0 | 0 | 0 | 0 |
| 0xFF | 0b11111111 | 8 | 1 | 0 | 0 |
Some points worth mentioning for what’s next:
ATis just one bit wide, and is stored as a bitstream in ATK1BSis basically the number of bits at one or zero, depending onAT(except for0x00and0xFF). It is stored as packed 4 bit numbers.BIis basically a base 10 encoding of the bits that are at one or zero (depending on AT)
Moreover, as you can see in the table above, the BI value can be bigger than one byte. That being said, there is only 99 possible different values (run len(set(EncodedData(v).BI for v in range(256))) to convince yourself). We can thus encode this value on one byte, with a fixed substitution table to recover the original value. Such a table is included in the AlphaTav software. The important thing to remember here is that the MSB bit of an encoded BI value will always be zero. This will be very important for what’s next.
The ATK3 file
This file is actually a TIFF image. It contains mainly two things:
inside its copyright metadata: encryption key material used in various key derivation process. The actual key used for the AES/3DES/RC2 algorithm is derived from these information. The important point here is that no user key material is necessary to compute this key.
encoded inside the value of its green pixels (!): a serialized .Net object containing information about the encryption algorithm used for
ATD/ATK1/ATK2. It also contains the various “restrictions”. This is encrypted with key material derived from the copyright metadata above, so we are always able to decrypt it.
Using a serialized .Net object doesn’t seem the best choice for interoperability with non .Net platforms, and might also be a security risk.
Moreover, as we just said, deserializing a .Net object from something else than a .Net virtual machine is not that trivial. I’ve built a construct-based python module for this, that does not support the whole format, but is enough for the need of this challenge: dotnetDeser.
Keystream derivation process
What is called “keystream” is a fixed amount of bytes that is generated out of many information, thanks to a PBKDF2 function:
- the user password (if used any)
- the PIN code
- additional restriction information (e.g. hardware ones), that you can just gather from ATK3
The length of this keystream depends on the length L of the user password. The formula is #(KS) = clamp(100*L, 1024, 131072).
The user password and PIN code, among with information extracted from ATK3, are used to generate something called a “factor table”. We don’t really need to understand that part to crack the challenge, so it will be left aside for the sake of consistency.
This factor table, along with the additional restriction, are all mixed together through a PBDKF2 function to finally generate the keystream. It is interesting to note that a first version that I have reversed directly used the “factor table” as a keystream (and that’s why the keystream is still called “factor table” in various places of the PoC code).
Obviously, in these information, we don’t have the user password and the PIN code, so no direct way to regenerate that keystream.
It is also important to notice that, once we have this keystream, we can fully retrieve the encrypted zip. Indeed, it gives the IV for the AES/3DES/RC2 algorithms, and their key is already known thanks to ATK3.
The cracking algorithm
Keystream reuse and retrieval
That being said, the main vulnerability in this design is that this fixed length keystream is reused multiple times to XOR data, and not only inside the same file, but also accross ATD & ATK1 (ATK2 isn’t XORed with this keystream).
Let’s take a closer look at how this keystream is used:

Before trying to exploit known clear text to recover that keystream, we need to be able to decrypt and ungzip ATD/ATK1/ATK2. According to our scheme, they are encrypted using either AES, 3DES or RC2 in CBC mode. The key is known (derived from information in ATK3), but the IV is unknown, as it is the first bytes of the keystream we are trying to recover. But let’s take a look at how CBC work:
 From Wikipedia
From Wikipedia
Not knowing the IV only makes the first block unavailable. In the case of AES, it is thus 16 bytes. In the case of 3DES or RC2, it is 8 bytes. Now, let’s take a look at what a GZip file looks like, to see what we lose:
 Scheme by Corkami
Scheme by Corkami
In our cases, the first 8 bytes are, for instance:
1F 8B: header08: use DEFLATE (always the case)00: no flags (so no filename)66 59 59 3A: timestamp (we don’t care)
So, if ATD, ATK1 or ATK2 is encrypted using 3DES or RC2, then we can fully decompress the underlying DEFLATE stream. In the case of AES, we miss the first 8 bytes of the actual DEFLATE stream. The end of this blog post describes how we can still recover almost all the decompressed data even in this case. Note that, for the actual challenge container, this is not really an issue as none of the files are encrypted with AES (did someone say this was a CTF?).
With all these information in mind, let’s formalize a bit the cracking algorithm.
Hunting for known plaintext
Let’s consider we are able to ungzip ATD, ATK1 and ATK2. The only remaining unknown information is still the fixed length keystream (now named KS). As it is reused within the same file and for ATD & ATK1 with a XOR operator, knowning the data that has been fed to the fragmentation algorithm will give us known Bit Indexes (BI) and AlphaTav (AT) clear values, and hence known bits of KS. The scheme below describes this attack:

So let’s hunt for known data!
The first thing to notice is that the data that are fed to the fragmentation algorithm are not the actual user files, but an encrypted zip version of them. We don’t need the password of this zip for now, even if it can be derived straight from ATK3. The important parts are:
- we can guess some known values from the zip format specification
- it is an encrypted and compress stream, so the values of this zip file can be considered as random ones
Thanks to the zip format
Let’s take a look at what a zip file look like:
 Scheme by Corkami
Scheme by Corkami
As we can see from this scheme, there are some fixed signatures we can use as known data. This is what we do as a first bootstrap step. In the case of the challenge, this helps recover approximately 12% of the keystream.
Thanks to block sizes (in ATK2)
If we look carefully at the decryption scheme, we see that ATK2 isn’t xored with KS. This means we have direct access to the Block Sizes (BS) part of the fragmented data. Moreover, one interesting fact of the fragmentation algorithm is that if BS == 0, then we can have only two original clear values: 0x00 or 0xFF. The discrimination is made thanks to the associated AlphaTav (AT) bit.
Coupled with the fact that the fragmented data are the ones of an encrypted zip stream, it means that the probability of having an original unfragmented value of 0x00 or 0xFF is 2/256. For big containers that are a few megabytes, as we have already recovered a few bits from KS thanks to the zip format (and thus some AT values), our experiences show we usually manage to figure out enough 0x00 or 0xFF original values for the zip stream, and with them what remains of KS. In the case of the challenge, the container is around 460Mb, so we have plenty of data to run the attack and make it successful.
We can also notice that there is some form of “avalanche” effect, due to the fact that KS is reused repeatedly across the same file, and across ATD/ATK1 & ATK2. Indeed, if we manage to recover at least one new bit of KS with this technique, it means we might recover new bits of KS by just rerunning this part of the algorithm from the beginning, and so on. In the case of the challenge, only one run was necessary to fully recover KS (as this is a relatively big container).
We also think there is an interesting math exercise that would compute the probability of success of this attack given the size of the original container (considering the number of already known KS bits).
Figuring out the keystream length
One thing we didn’t discuss yet is how to find the length of KS, which is, as a reminder, #(KS) = clamp(100*L, 1024, 131072) (with L the length of the user provided password, which is unknown).
One interesting thing we have noticed during the analysis of the fragmentation algorithm is that the maximum value for AT is 99, so the MSB of AT will always be 0. So if we take two different blocks of ATD data of length N whose index is aligned on N bytes, and XOR-ing these two blocks gives at least one byte with its MSB equals to 1, it means we have guessed a wrong value for #(KS).
Moreover, reverse engineering the AlphaTav software shows that the password length L is between 10 and 1310. So we have 1300 possibilities for L, and thus for #(KS) (clamping does not change this), which is easily bruteforcable with this technique.
Then, once we have figured out candidates for #(KS), we verify that we don’t find any inconsistencies while guessing clear texts. Indeed, if two clear texts at various positions provides two different bits for KS, it means #(KS) isn’t valid (considering there are no errors in the guessed clear texts).
In practice, we can crack the challenge with the first L value guessed.
The zip password
The zip password is basically a number called TimeKey stored in the serialized .Net object in ATK3. It is more precisely the base 8 representation of this number as a string. The important point is that it does not depend on any user supplied key material, and so is always computable given only ATK3.
Incomplete GZip streams
There’s this problem of incomplete GZip stream we left aside previously.
As a reminder, we are in a situation where we are missing the first 16 bytes of a GZip file. As seen above, a GZip file is basically a wrapper around a compressed stream. DEFLATE is the only one officially supported, according to RFC 1952. This is also the algorithm used in the files generated by AlphaTav. So, in the end, what we are missing is the beggining of the DEFLATE stream.
So let’s take a high-level view at DEFLATE streams:

A DEFLATE stream is a bit-stream, built around blocks. Each block defines a type of data, which is either raw/uncompressed data, or compressed Huffman data using a static or dynamically computed tree.
To still decompress as much data as possible, the general idea is to first find the bit index of the next block, and then decompress the DEFLATE stream starting from this block. Doing this, it is important to note that one block can point to data from the previous blocks, up to 32 kb. If such a thing happens, we generate unknown bytes in the recovered stream. We thus end up with a stream with unknown bytes at the beginning, and this can happen until backtracking only points to known data. This is illustrated in the scheme below:

Finding the bit index of the next block is done by bruteforcing it:
- we start at bit
Xin the DEFLATE stream - we launch a full decompression of the stream. If some data are found to be incoherent, add 1 to
Xand go to 1. - if we found the last block, make sure it is actually the end of the DEFLATE stream. If not, add 1 to
Xand go to 1. Otherwise, the position of the next valid block isX.
Doing this, we manage to partially decompress the DEFLATE stream. The only thing we don’t know is how much decompressed data are missing at the beginning. We need this information, otherwise we can’t “align” ATD, ATK1 and/or ATK2. Fortunately (again), the GZip format provides, as its four last bytes, the size of the original data (DecompSize). So, we have exactly DecompSize-PartialDecompSize unknown bytes at the beginning of the partially decompressed data.
To implement this algorithm, we tweaked the excellent pure Python DEFLATE implemention by Project Nayuki.
In practice, in the tests we’ve done, recovering the index of the next block only takes a few seconds, and we manage to recover around 99.9% of the decompressed data.
Cracking the challenge
As said previously, the challenge is an AlphaTav container. On the 2019-10-11, Ex0-Sys published the last (ATK3) of the four files (ATD, ATK1, ATK2, ATK3), allowing us to launch our attack.
In this case, ATD/ATK1/ATK2 are encrypted with, respectively, RC2/3DES/3DES. We are thus lucky enough not to have to deal with the partial GZip stream issue. Moreover, as the container is 460MB, we had plenty of known bits to play with, and the keystream is successfully retreived in less than a minute (what actually takes of the time is decrypting and decompressing the AT* files in Python).
Once cracked, we are left with a zip file that contains a video to claim the bounty, and another AlphaTav container named Bounty Challenge BTC Wallet.at{d,k1,k2,k3}.
Bonus: container with the Electrum wallet
Cracking the previous container was enough to claim the bounty, but we were curious about this new container. Here, ATD/ATK1/ATK2 are encrypted with, respectively, AES256/AES256/3DES. We have thus to deal with the partial GZip stream issue. Fortunately, our partial decompression algorithm allows us to recover 99.9% of ATD and ATK1, giving plenty of data to run our keystream recovery attack.
After cracking the container, we are left with an electrum wallet, whose passphrase is unknown to us (at that time).
Conclusion
As stated in the title of this article, this somehow looked like a CTF, as for every step of the algorithm there was always something possible to achieve to move to the next one (e.g. having reliable clear text values thanks to the zip format, being able to still retrieve partial DEFLATE streams, etc). The core of the attack is the reuse of a fixed keystream to XOR various data, and everything we do in the attack is about finding known clear/encrypted data to recover that keystream. As a side note, we also haven’t seen any integrity checks in the container, but might have missed it.
The Ex0-sys team was professional in handling their bounty program. They had the real desire to improve their technology. That being said, I think this proves once again that cryptosystem designs should be open and their implementation easily reviewable by everyone. The only secrets should be various key materials.
Kerckhoff was right, once again.
Timeline
- 2019-10-11: challenge broken in the morning (publication of the ATK3 file), sending of the proof by mail
- 2019-10-11: acknowledgment by the ex0-sys team
- 2019-10-13: sending of a PoC that decrypts the challenge
- 2019-10-16: acknowledgment that the PoC works. ex0-sys also provides the wallet password.
- 2019-10-21: authorization to present this work at a private conference in Paris
- […]: procrastinating this blog post
- 2021-01-30: publication of this blog post
Acknowledgments
I would like to thank Ange Albertini for providing the very nice Zip and GZip file format description images.
Also thanks to toffan, patate & acid for reviewing this blog post!